Refactoring - Improving The Backtesters Design
Table Of Contents
Recap
Refactoring
Design != Code
Embrace Chaos
Backtester Design
Fetch Data Implementation
Building The Test Harness
Coding To Design
The Post-Cost SR Design
Creativity != Complexity
Next Up
Recap
Please look here for a proper recap. In todays article we're going to prepare our backtester and start refactoring the implementations of all the interfaces we've built into it over the last few issues. The code got quite messy over the last few iterations. We continued to hackily add and add stuff and didn't take the time to clean up afterwards. It is now time!
Refactoring
But first, let's talk a little bit about refactoring. Refactoring is the process of changing code (or any system really) to improve its internal structure. A healthy structure is the key to stress-free software management. It makes the code more readable and easily modifiable. The problem with refactoring is that it's inherently risky. It requires changing existing implementations, which - if done wrong - introduces bugs that can change its behaviour without notifying you.
"To avoid digging your own grave, refactoring has to be done systematically"
- Martin Fowler
In essence, we want to improve the existing codes structure without changing its behaviour. How can we do that? How can we be sure that we don't accidentally alter its behaviour? After all, anyone who has worked with software has probably lived through at least one adventurous experience of hunting down bug after bug after changing their code slightly.
In modern software development, every crucial line of code is usually accompanied by way more lines of testing code. The purpose of this testing code is to check intended behaviour and notify the developer if something broke. Each time you make a change, the code runs "through" this testing suite and then spits out indicators for every test that passed or failed. If some of them failed, you need to circle back and re-edit or even roll back your changes and start over. Only when all tests are green, you're allowed to move on. So the cycle goes:
- make changes
- run test suite
- fix fails (make changes)
- repeat
We don't have a testing suite yet but we also don't really need one. Remember, we still have our assert() calls in place to protect us from unwanted behaviour changes by our refactorings. Since we pinned the price history to a specific date, all the inputs and outputs are the exact same every time. We can continue to rely on our assert() calls until we start working with more complex scenarious like continuous streams of live data.
Design != Code
Software development distinguishes between design and implementation. The design of a system covers everything about what has to be done wheras the implementation takes care of the details about how it has to be done, what language to choose etc. A good design always comes first! Coding then comes second. It doesn't always have to be well thought out or done using UML diagrams before your start implementing. But you should at least have a rough high-level idea of what you're trying to accomplish before hammering away in your code editor.
This is not to say that refactoring is only needed if we did something "wrong" in the beginning. In fact, the old way of identifying and defining every little use case and detail before starting has time and time again proven to be the wrong model for most modern software projects. Waterfall is dead! Even if you've laid out the perfect design, over time the requirements will change and the code will be modified, challenging the integrity of it and pushing its structure away from the design more and more. With refactoring, you can take any code base and start molding it back into a well structured and designed one.
Embrace Chaos
This makes refactoring a perfect tool for more of an evolutionary development process with shorter, iterative cycles. It enables us to quickly sketch out an idea and hack it into the current implementation as fast as possible without breaking it. This is a great way to gather immediate feedback on the idea without the need to adhere to proper coding or even design standards. We can answer questions like does it integrate well with our current solution, is it working as intended, does it break things etc. right away. If everything is fine (tests are green), we can refine the hacky stuff into proper code and then move on to the next iteration of our system and redefine design and implementation to current requirements.
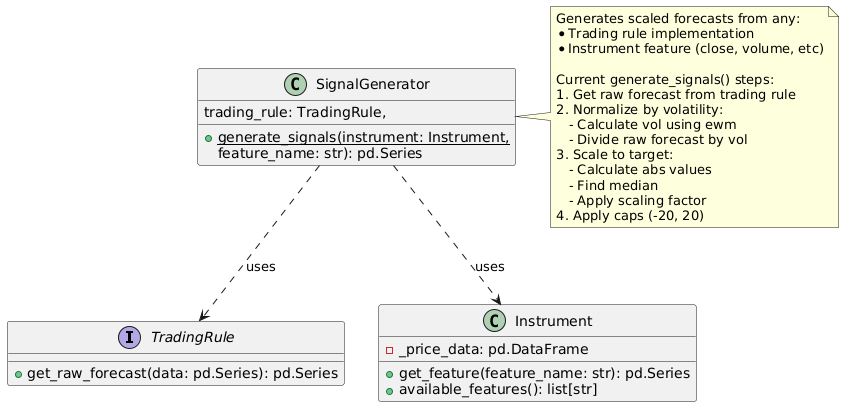
Backtester Design
Let's identify the design and some of the implementations of our current backtester to highlight the differences between them. Since the backtester isn't really the whole system but just one component, we're going to limit the discussion to the backtesters current flows of logic:
The design:
- Fetch historical price data for instrument to trade
- Configure instrument specs (contract details, trading timeframe, fee structure, etc.)
- Generate trading signals
- Calculate position size
- Simulate trading
- Calculate pre-cost performance metrics
- Calculate post-cost performance metrics
- Generate performance report
Now all of these are worded pretty abstract - and this is by choice! The design of a system doesn't care about the specifics and details. Its only job is to convey the high-level requirements of what we need to do to get the job done, not how it has to be done. Each step in the above flow can be escalated the same way. Fetch historical price data for example can be expanded to:
Fetch historical price data:
- Fetch raw data from data source for instrument
- Clean and prepare data
- Resample data to trading frequency
- etc.
The steps are getting somewhat more specific but still do not offer any opinion about what data source to choose, etc. This all goes into the implementation!
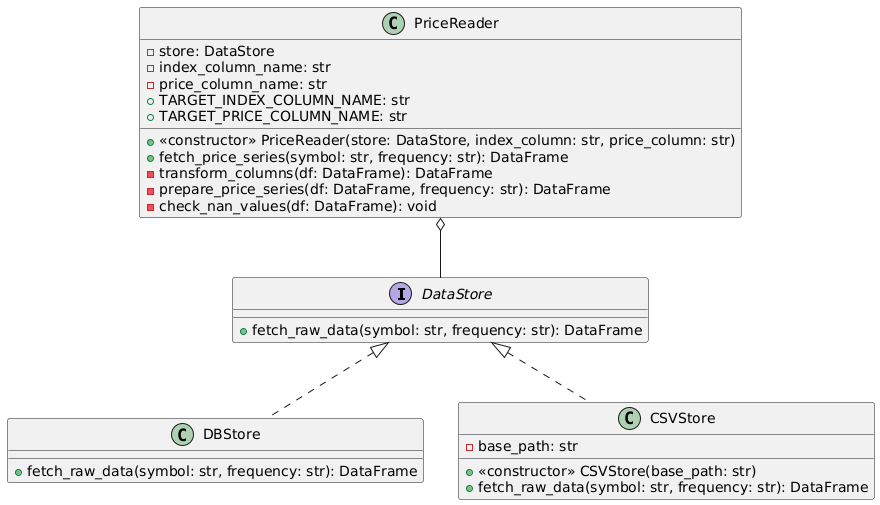
Fetch Data Implementation
Now let's look at its implementation. I've annotated the corresponding design bits with comments in the code to map them:
Fetch data implementation:
[...]
#Contract Specs (just for context)
symbolname = 'BTC'
resample_period = '1D'
[...]
# Connect to datasource
import pandas as pd
from dotenv import load_dotenv
import psycopg2
load_dotenv()
conn = psycopg2.connect(
dbname=os.environ.get("DB_DB"),
user=os.environ.get("DB_USER"),
password=os.environ.get("DB_PW"),
host=os.environ.get("DB_HOST"),
port=os.environ.get("DB_PORT")
)
cur = conn.cursor()
cur.execute(f"""
SELECT ohlcv.time_close, ohlcv.close
FROM ohlcv
JOIN coins ON ohlcv.coin_id = coins.id
WHERE coins.symbol = '{symbolname}'
ORDER BY ohlcv.time_close ASC;
""")
# Fetch raw price data
rows = cur.fetchall()
cur.close()
conn.close()
# (Clean and) Prepare data
df = pd.DataFrame(rows, columns=['time_close', 'close'])
df['time_close'] = pd.to_datetime(df['time_close'])
if not pd.api.types.is_datetime64_any_dtype(df['time_close']):
df['time_close'] = pd.to_datetime(df['time_close'])
df.set_index('time_close', inplace=True)
df.sort_values(by='time_close', inplace=True)
# Resample Data
df = df.resample(resample_period).last()
As you can see, the implementation looks awfully different than the design. It's not different though! It talks about the same thing but on another level in the chain. One is just text and the other one is python code. We can change the implementation all day long by refactoring code, using other languages, other data sources, etc. without affecting its design at all.
To accomplish this, the only thing we have to worry about is staying true to the design. This is where refactoring comes into play. Before we start the refactoring cycle, we need to set up a guird system that tests against the interface of the design rather than its implementation.
Building The Test Harness
As already stated, we're going to continue to rely on our assert() calls to confirm that the codes behaviour doesn't change while we're working on it, improving its structure.
#backtest_refactored.py
assert (strat_tot_return == 958.3412684422372)
assert (strat_mean_ann_return == 65.7261486248434)
assert (strat_std_dev.iloc[-1] == 1.8145849936803375)
assert (strat_sr.iloc[-1] == 1.8958956813694106)
assert (df['fees_paid'].sum() == 1038.6238698915147)
assert (df['slippage_paid'].sum() == 944.2035180831953)
assert (df['funding_paid'].sum() == 3130.3644113437113)
assert (ann_turnover == 37.672650094739545)
assert (rolling_pre_cost_sr.iloc[-1] == 1.9914208916281093)
assert (rolling_post_cost_sr.iloc[-1] == 1.8958956813694112)
assert (strat_rolling_trading_costs_sr.iloc[-1] == 0.09552521025869809)
If we run this, we get the error NameError: name 'strat_tot_return' is not defined. That's fine, we just copy-pasted the assert() calls from our backtester only. Nothing should be working at this point! Let's iterate through it by fixing the error and run it again. We're going to put in the least amount of work possible to fix it, then move on to the next error, etc.
strat_tot_return = 958.3412684422372
assert (strat_tot_return == 958.3412684422372)
[...]
# New error after running the backtest_refactored.py again:
#
# NameError: name 'strat_mean_ann_return' is not defined
Let's fix that one too (and all the others after that). We're also going to rename the variables and group them a little differently:
strat_total_perc_return = 958.3412684422372
assert (strat_total_perc_return == 958.3412684422372)
strat_mean_ann_perc_return = 65.7261486248434
assert (strat_mean_ann_perc_return == 65.7261486248434)
strat_std_dev = 1.8145849936803375
assert (strat_std_dev == 1.8145849936803375)
strat_pre_cost_sr = 1.9914208916281093
assert (strat_pre_cost_sr == 1.9914208916281093)
strat_post_cost_sr = 1.8958956813694112
assert (strat_post_cost_sr == 1.8958956813694112)
fees_paid = 1038.6238698915147
assert (fees_paid == 1038.6238698915147)
slippage_paid = 944.2035180831953
assert (slippage_paid == 944.2035180831953)
funding_paid = 3130.3644113437113
assert (funding_paid == 3130.3644113437113)
ann_turnover = 37.672650094739545
assert (ann_turnover == 37.672650094739545)
If we run this script, we get no errors! Great! Now you might be asking yourself "what the heck is this interface he was talking about before? Didn't we just test for exact implementation outputs?" Yes, we did! This is fine because we're still relying on EOD prices that are pinned to an exact date. Inputs and outputs will always stay the same. The current test suites purpose is to make restructuring our code to the designs interface as easy as possible. Later on we're going to switch out the assert() calls to some more sophisticated testing techniques. But only if the requirements need us to!
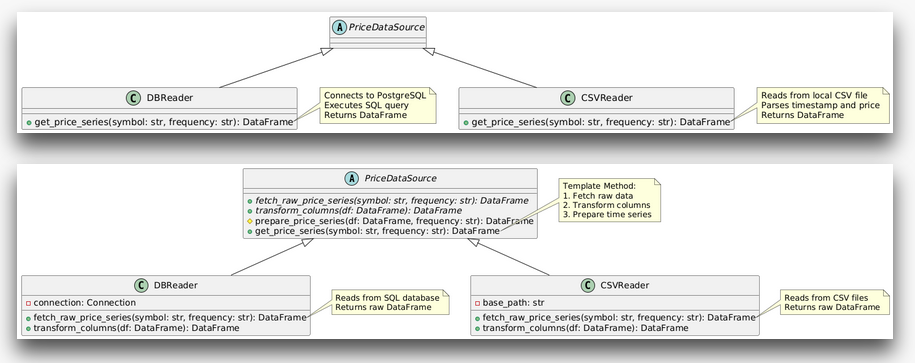
Coding To Design
Our test-suite is set up. We can start working on the code. The first thing we need to do is to switch out the logic behind the variables referenced in the assert() calls. Right now they have no logic but literal values. We want to reference more abstract interfaces instead. To adhere to the design, we need to know its current logic first!
The Calculate Performance Metrics Design:
- Calculate strategies total percentage returns
- Calculate strategies annual mean percentag returns
- Calculate strategies standard deviation
- Calculate strategies pre-cost Sharpe Ratio
- Calculate strategies post-cost Sharpe Ratio
def calculate_strat_total_perc_returns():
pass
def calculate_strat_mean_ann_perc_return():
pass
def calculate_strat_std_dev():
pass
def calculate_strat_pre_cost_sr():
pass
def calculate_strat_post_cost_sr():
pass
strat_total_perc_return = calculate_start_total_perc_returns()
assert (strat_total_perc_return == 958.3412684422372)
strat_mean_ann_perc_return = calculate_strat_mean_ann_perc_return()
assert (strat_mean_ann_perc_return == 65.7261486248434)
strat_std_dev = calculate_strat_std_dev()
assert (strat_std_dev == 1.8145849936803375)
strat_pre_cost_sr = calculate_strat_pre_cost_sr()
assert (strat_pre_cost_sr == 1.9914208916281093)
strat_post_cost_sr = calculate_strat_post_cost_sr()
assert (strat_post_cost_sr == 1.8958956813694112)
If we run this, we get the error assert (strat_total_perc_return == 958.3412684422372) AssertionError. Of course we get this error, we don't return anything from the function called to get the strat_total_perc_return yet. We simply added it as an abstract interface so we can switch out its implementation without the need to reference its output differently in the assert() call. The function calculate_strat_total_perc_returns() now bridges the gap between the interface specified in our design - 1. Calculate strategies total percentage returns - and its implementation. To get rid of the error, we're simply going to return the values again for now.
def calculate_start_total_perc_returns():
return 958.3412684422372
def calculate_strat_mean_ann_perc_return():
return 65.7261486248434
def calculate_strat_std_dev():
return 1.8145849936803375
def calculate_strat_pre_cost_sr():
return 1.9914208916281093
def calculate_strat_post_cost_sr():
return 1.8958956813694112
See what we did there? The implementation changed but the design didn't! The overall logic is still the same even though we juggled the code.
The Post-Cost SR Design
If you look closely, you'll see that we got rid of the assert() calls concerning costs in the above code snippet.
assert (fees_paid == 1038.6238698915147)
assert (funding_paid == 3130.3644113437113)
assert (slippage_paid == 944.2035180831953)
We also didn't list them in Calculate Performance Metrics Design. This was on purpose! I made a desing decision on the fly to tuck them away as a detail inside the 5. Calculate strategies post-cost Sharpe Ratio step. How do we model this into our code structure so it reflects that design decision?
The Calculate Strategies Post-Cost SR Design:
- Get pre-cost Sharpe Ratio
- Deduct Fees/Commissions
- Deduct Holding Costs (Rolling/Overnight Holding/Funding)
- Deduct Slippage (Spread)
[...]
def calculate_strat_post_cost_sr(pre_cost_sr):
fees = 0.09552521025869809
holding_costs = 0
slippage = 0
return pre_cost_sr - (fees + holding_costs + slippage)
strat_pre_cost_sr = calculate_strat_pre_cost_sr()
assert (strat_pre_cost_sr == 1.9914208916281093)
strat_post_cost_sr = calculate_strat_post_cost_sr(strat_pre_cost_sr)
assert (strat_post_cost_sr == 1.8958956813694112)
We can make it even more granular by providing more interfaces:
def calculate_fees_paid():
return 1038.6238698915147
def calculate_holding_costs_paid():
funding_paid = 3130.3644113437113
return funding_paid
def calulcate_slippage_paid():
return 944.2035180831953
def calculate_strat_post_cost_sr(pre_cost_sr):
fees = calculate_fees_paid()
holding_costs = calculate_holding_costs_paid()
slippage = calulcate_slippage_paid()
fake_offset = 0.09552521025869809
return pre_cost_sr - fake_offset
# return pre_cost_sr - (fees + holding_costs + slippage)
fees_paid = calculate_fees_paid()
assert (fees_paid == 1038.6238698915147)
slippage_paid = calulcate_slippage_paid()
assert (slippage_paid == 944.2035180831953)
funding_paid = calculate_holding_costs_paid()
assert (funding_paid == 3130.3644113437113)
calculate_fees_paid(), calculate_holding_costs_paid() and calculate_slippage_paid() are now referenced instead of their literal values. The only thing we care about for confirmation is that the end result is correct.
All cost considerations are now taken care of in their own interfaces deep down in the tree. We don't have to think about them when looking further up the chain. We don't care about how exactly costs are calculated when trying to improve the design of 3. Generate trading signals, 6. Calculate pre-cost performance metrics or 8. Generate performance report and plots so it doesn't really make sense to type it all out right on the spot. The only time we're concerned with costs is when we need to think about how to 7. Calculate post-cost performance metrics. We don't want this detail to clog up mental space otherwise.
Creativity != Complexity
How far you want to take this and how much extra steps you want in each branch of your design tree is a call you have to make yourself. The only thing holding you back is your creativity. There are lots of useful design best practices but the most important of all is to keep things simple!
Even if you already have a sophisticated solution, that's way more performant, in the back of your head, try resisting the urge to implement it that way instantly. Your main focus when designing things should always be simplicity.
After you've gone through enough iterations and came to the conclusion that the design is now perfectly modeled to the exact requirements, you still can change and improve things. But at that time you'll already have a solid testing framework in place. Making changes - even in production environments - will become way less stressful and disruptive.
The full code - which isn't much at all - can be found here.
Next Up
All of the above lays out the high-level framework I'm using when approaching any codebase. It's only a super simple toy example but should make the key points of it all very clear. I use this framework to start things from scratch and also when working with legacy codebases. It works the same in every context.
In the next article we're going to go through each of the main design steps, breaking them down further and implementing its details by copy-pasting the real logic from our existing backtest.py. After that we're going to polish things off with better implementations of specific interfaces like cost considerations, data fetching, etc.
So long, happy coding!
- Hōrōshi バガボンド
Newsletter
Once a week I share Systematic Trading concepts that have worked for me and new ideas I'm exploring.
Recent Posts